The Vigenère Cipher: Frequency Analysis

Some early ciphers used only one letter keywords.
This is the so-called simple substitution cipher
or mono-alphabetic cipher.
In general, given two integer constants a and b,
a plaintext letter x is encrypted to
a ciphertext letter (ax+b) mod 26.
If a is equal to 1,
this is Caesar's cipher.
In fact, if we choose a keyword of length 1 in a Vigenère cipher,
it becomes Caesar's cipher.
Because of this, the encryption and decryption algorithms discussed
in Algebraic Nature
have all the ingredients for encryption and decryption.
The χ2 method
is an effective way to decrypt a ciphertext encrypted using a simple substitution method,
because there is only letter in the keyword and hence only one coset.
Therefore, we just choose the keyword length to be 1 and use the
χ2 method to find the best fit.
The χ2 method is a goodness-of-fit measure that works on two sequences
of values.
In our case, the two sequences of values are:
the English letter frequency and the letter frequency of a particular shift of the only coset.
The shift of a coset that yields the smallest χ2 is likely
to be encrypted by the corresponding letter of that shift.
Hence, shifting the coset 26 times and finding the letter that has the smallest
χ2 value will likely find the single-letter keyword.
Consider the following ciphertext encrypted with Caesar's cipher:
The following table has the χ2 value of each shift.
Since the χ2 value corresponding to the letter
T is the smallest,
the above ciphertext is very likely encrypted by
T.
YKBXG WLKHF TGLVH NGMKR FXGEX GWFXR HNKXT KLBVH FXMHU NKRVT
XLTKG HMMHI KTBLX ABFMA XXOBE MATMF XGWHE BOXLT YMXKM AXFMA
XZHHW BLHYM BGMXK KXWPB MAMAX BKUHG XLLHE XMBMU XPBMA VTXLT
KMAXG HUEXU KNMNL ATMAM HEWRH NVTXL TKPTL TFUBM BHNLB YBMPX
KXLHB MPTLT ZKBXO HNLYT NEMTG WZKBX OHNLE RATMA VTXLT KTGLP
XKWBM AXKXN GWXKE XTOXH YUKNM NLTGW MAXKX LMYHK UKNMN LBLTG
AHGHN KTUEX FTGLH TKXMA XRTEE TEEAH GHNKT UEXFX GVHFX BMHLI
XTDBG VTXLT KLYNG XKTE
| A | B | C | D | E | F | G | H | I | J | K | L | M |
| 11.7 | 11.4 | 12.9 | 3.79 | 16.1 | 5.56 | 4.08 | 3.13 | 19.1 | 9.90 | 5.04 | 13.3 | 14.2 |
| N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 18.8 | 21.1 | 7.18 | 6.39 | 9.75 | 4.99 | 0.0852 | 17.9 | 8.64 | 15.0 | 7.87 | 26.5 | 2.72 |
The following image has two frequency graphs. The horizontal axis has the 26 English letters, and the vertical axis shows the frequency values. The black line is the typical English letter frequency as shown in the English Frequency Table, and the blue line shows the frequency of each letter resulted from the T shift. It is very clear that both frequency graphs match with each other very well. Consequently, we are very confident that the ciphertext is encrypted using the keyword letter T.
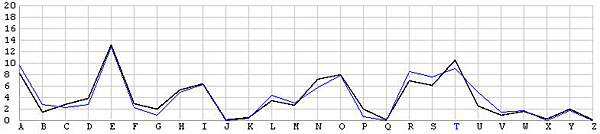
The following is the decrypted plaintext with punctuation and spaces added. This is Mark Anthony's funeral speech in Shakespeare's Julius Caesar.
Friends, Romans, countrymen, lend me your ears;
I come to bury Caesar, not to praise him.
The evil that men do lives after them;
The good is oft interred with their bones;
So let it be with Caesar. The noble Brutus
Hath told you Caesar was ambitious:
If it were so, it was a grievous fault,
And grievously hath Caesar answer'd it.
Here, under leave of Brutus and the rest--
For Brutus is an honourable man;
So are they all, all honourable men--
Come I to speak in Caesar's funeral.
Let us look at the frequency graphs of some incorrect shifts. The following images show the shifts from T backward to L. In the T shift there is a peak at the letter E. As the shift changes from T to L, this peak moves to the right from E to N. In fact, as we move from the T shift to the left one position at a time, the peak moves from E to the right one position at a time. This is not a surprise at all, because Example 3 of the Index of Coincidence page demonstrated that a simple shift cipher shifts the frequency the same number of positions. Based on this observation, a frequency analysis, simply put, is just drawing the frequency graph of a particular shift and slide this frequency graph to the left or right until it matches the given English frequency graph as close as possible. The best match yields the unknown keyword letter.
| T | |
| S | 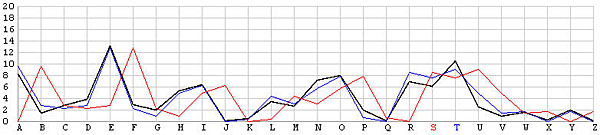 |
| R | 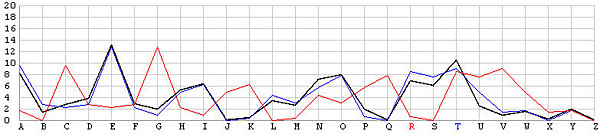 |
| Q | 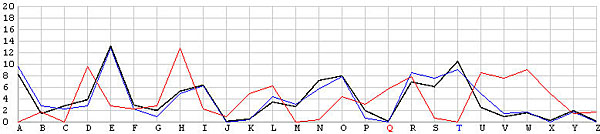 |
| P | 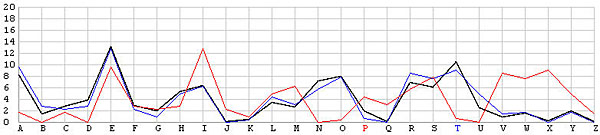 |
| O | 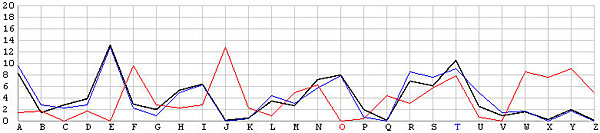 |
| N | 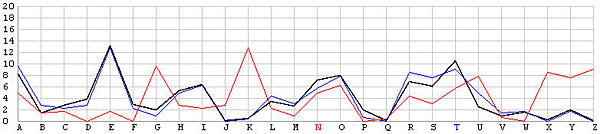 |
| M | 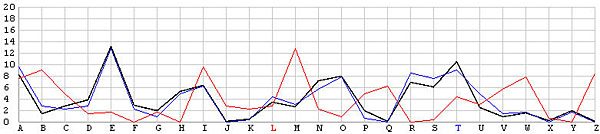 |
| L | 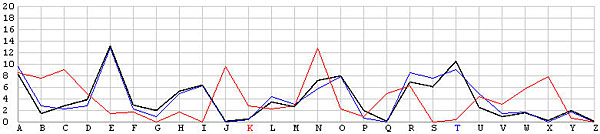 |
Example 1
Consider the following ciphertext encrypted by a keyword of one letter.
GODRO ZOYZV OYPDR OEXSD ONCDK DOCSX YBNOB DYPYB WKWYB OZOBP
OMDEX SYXOC DKLVS CRTEC DSMOS XCEBO NYWOC DSMDB KXAES VSDIZ
BYFSN OPYBD ROMYW WYXNO POXMO ZBYWY DODRO QOXOB KVGOV PKBOK
XNCOM EBODR OLVOC CSXQC YPVSL OBDID YYEBC OVFOC KXNYE BZYCD
OBSDI NYYBN KSXKX NOCDK LVSCR DRSCM YXCDS DEDSY XPYBD ROEXS
DONCD KDOCY PKWOB SMK
Of the 26 possible shifts, the K produces the smallest χ2 of 0.063, and, as a result, the ciphertext is encrypted by K. The following is the decrypted message using keyword K:
WETHE PEOPL EOFTH EUNIT EDSTA TESIN ORDER TOFOR MAMOR EPERF
ECTUN IONES TABLI SHJUS TICEI NSURE DOMES TICTR ANQUI LITYP
ROVID EFORT HECOM MONDE FENCE PROMO TETHE GENER ALWEL FAREA
NDSEC URETH EBLES SINGS OFLIB ERTYT OOURS ELVES ANDOU RPOST
ERITY DOORD AINAN DESTA BLISH THISC ONSTI TUTIO NFORT HEUNI
TEDST ATESO FAMER ICA
Adding punctuation and spaces to the above decrypted text we have the following, which is the preamble of the United States Constitution:
We the People of the United States,
in Order to form a more perfect Union, establish Justice,
insure domestic Tranquility, provide for the common defence,
promote the general Welfare, and secure the Blessings of Liberty
to ourselves and our Posterity, do ordain and establish this
Constitution for the United States of America.
Next, let us look at the other 25 incorrect shifts. The following images show all 26 possible shifts. Since the most frequently occurring letter in English is the letter E, the peak in each frequency graph is the result of encrypting E by the unknown keyword letter. For example, in the frequency graph of the J shift, the peak is at letter F, which means the English letter E is encrypted to F if the unknown keyword letter is J. Of course, this is not true because the most commonly seen letter is E rather than F. The A shift has the most frequently occuring letter at O (i.e., E being encrypted to O by the letter A). As the shift goes from A to Z, the peak moves to the left from O to the left and appears at the left edge with the O shift. When the peak moves to the letter E for shift K, the frequency graph of shift K becomes very close to that of the English language frequency. Consequently, K is the letter used to encrypt the ciphertext and this observation agrees with that of the χ2 method. ♦
| A |  |
N |  |
|
| B |  |
O |  |
|
| C |  |
P |  |
|
| D |  |
Q |  |
|
| E |  |
R |  |
|
| F |  |
S |  |
|
| G |  |
T |  |
|
| H |  |
U |  |
|
| I |  |
V |  |
|
| J |  |
W |  |
|
| K |  |
X |  |
|
| L |  |
Y |  |
|
| M |  |
Z |  |
Once you understand the above example, the use of frequency analysis is just applying the same trick to each coset. In other words, 26 shifts are applied to a given coset, one for each English letter, and the one whose frequency graph matches the English frequency graph the best is the letter used to encrypt that coset. The χ2 method is just a mathematical tool to find this best match.
| |
|
|