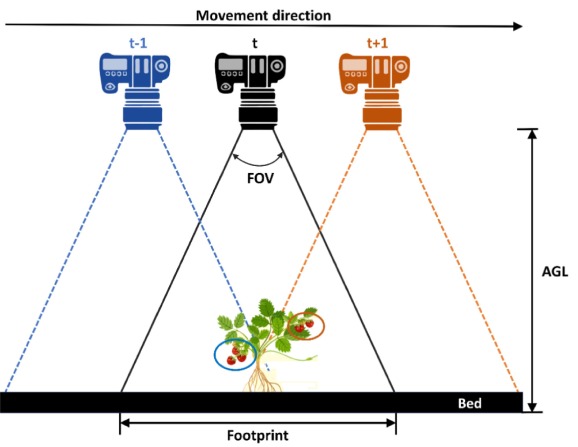


The methods used to analyze sUAS images have not been significantly changed to accommodate the wide adoption of these images in the natural resource management field. Currently, traditional pixel-based and object-based image classification of an orthoimage produced through photogrammetric processing of hundreds or thousands of sUAS images is still the most common way for sUAS image classification. Images captured by sUAS differ from those captured by other remote sensing platforms since they tend to have smaller extent, higher spatial resolution, and large image-to-image overlap with varying objectsenor geometry compared to satellite or piloted aircraft images. Unlike satellite images, in a typical image acquisition mission, many overlapped sUAS images are captured within a very short time from different viewing angles, potentially, facilitating a way to study the bi-directional reflectance distribution function (BRDF) of the land cover. Nevertheless, taking advantage of this redundancy in image classification is by itself an important asset to explore.
With the rapid evolution of deep learning classifiers, and increased availability of computing power (e.g., GPU and cloud computing), deep learning classifiers have become one of the most active topics for the sUAS image classification field. This is not only motivated by its successful performance in computer vision, but also due to its operational advantages in comparison with traditional classifiers. For example, deep learning classifiers do not require manual extraction of features, while manually selecting appropriate features are important to achieve good performance for traditional classifiers. Deep learning classifiers, however, are not without shortcomings. Generally, they require large amount of training data accompanied by a computationally intensive training process.
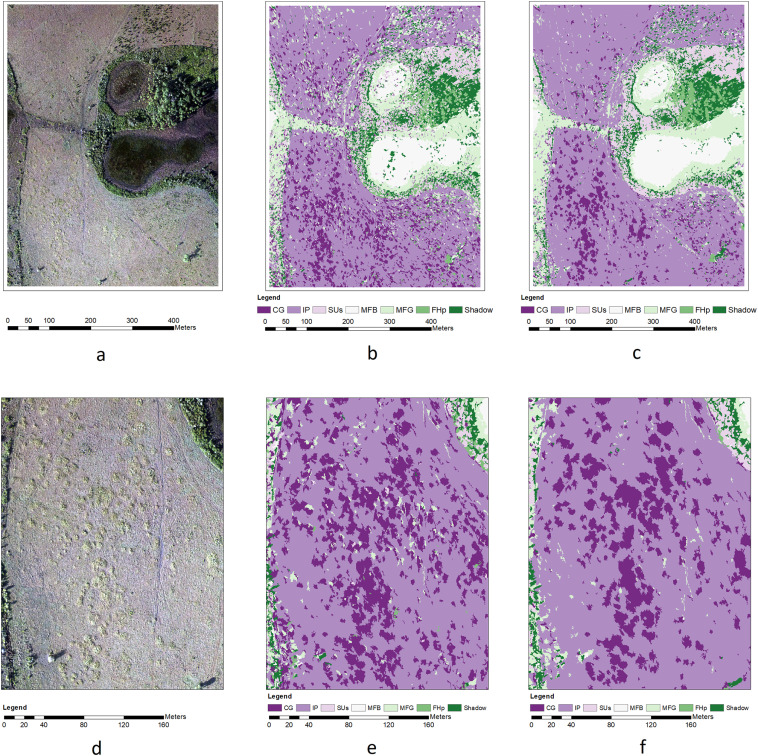
We introduce a new OBIA approach utilizing multi-view information of original UAS images and compare its performance with that of traditional OBIA, which uses only the orthophoto (Ortho-OBIA). The proposed approach, called multi-view object-based image analysis (MV-OBIA), classifies multi-view object instances on UAS images corresponding to each orthophoto object and utilizes a voting procedure to assign a final label to the orthophoto object. The proposed MV-OBIA is also compared with the classification approaches based on Bidirectional Reflectance Distribution Function (BRDF) simulation. Finally, to reduce the computational burden of multi-view object-based data generation for MV-OBIA and make the proposed approach more operational in practice, this study proposes two window-based implementations of MV-OBIA that utilize a window positioned at the geometric centroid of the object instance, instead of the object instance itself, to extract features. The first window-based MV-OBIA adopts a fixed window size (denoted as FWMV-OBIA), while the second window-based MV-OBIA uses an adaptive window size (denoted as AWMV-OBIA). Our results show that the MV-OBIA substantially improves the overall accuracy compared with Ortho-OBIA, regardless of the features used for classification and types of wetland land covers in our study site. Furthermore, the MV-OBIA also demonstrates a much higher efficiency in utilizing the multi-view information for classification based on its considerably higher overall accuracy compared with BRDF-based methods. Lastly, FWMV-OBIA and AWMV-OBIA both show potential in generating an equal if not higher overall accuracy compared with MV-OBIA at substantially reduced computational costs.
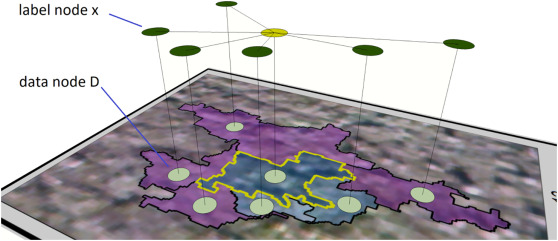
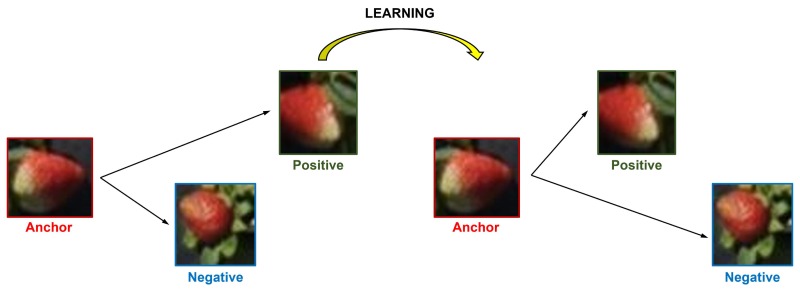
Context information is rarely used in the object-based landcover classification. Previous models that attempted to utilize this information usually required the user to input empirical values for critical model parameters, leading to less optimal performance. Multi-view image information is useful for improving classification accuracy, but the methods to assimilate multi-view information to make it usable for context driven models have not been explored in the literature. Here we propose a novel method to exploit the multi-view information for generating class membership probability. Moreover, we develop a new conditional random field model to integrate multi-view information and context information to further improve landcover classification accuracy. This model does not require the user to manually input parameters because all parameters in the Conditional Random Field (CRF) model are fully learned from the training dataset using the gradient descent approach. Using multi-view data extracted from small Unmanned Aerial Systems (UASs), we experimented with Gaussian Mixed Model (GMM), Random Forest (RF), Support Vector Machine (SVM) and Deep Convolutional Neural Networks (DCNN) classifiers to test model performance. The results showed that our model improved average overall accuracies from 58.3% to 74.7% for the GMM classifier, 75.8% to 87.3% for the RF classifier, 75.0% to 84.4% for the SVM classifier and 80.3% to 86.3% for the DCNN classifier. Although the degree of improvement may depend on the specific classifier respectively, the proposed model can significantly improve classification accuracy irrespective of classifier type.

